As announced on December 17, 2020, PASS saddened to share that, due to the impact of COVID-19, PASS is ceasing all regular operations, effective January 15, 2021. PASS will maintain access for members until January 15th. Please read the announcement from the PASS Board for more information.
The PASS encourage you to take full advantage of any access that you have to PASS content between now and January 15, 2021.
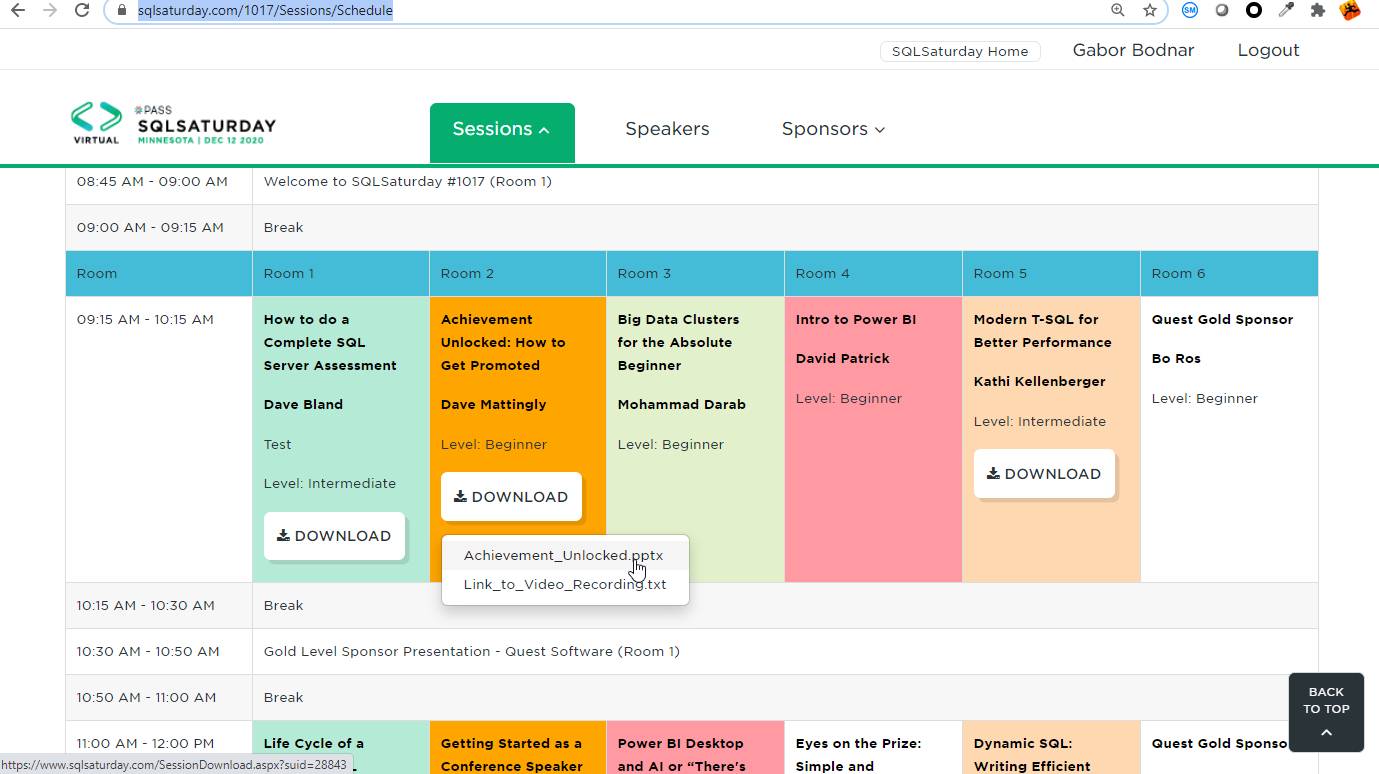
You can download them in the SQLSatruday website by manually:
Or you can download by script.
I created a simple script in python, which can download the files which is not required authentication. Why python? I started to study it two month ago, so I must have a real practice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# created by Gábor Bodnár 2020-12-24 # you can download SQLSaturday session files, which does not req authentication # order from the newest to older files in batch . The latest is: 28874 # https://www.sqlsaturday.com/SessionDownload.aspx?suid=28865 # https://www.sqlsaturday.com/SessionDownload.aspx?suid=16007 # https://www.sqlsaturday.com/SessionDownload.aspx?suid=28134 (you can download from logged in site) import sys import os import ntpath import wget from shutil import move from colorama import init init() # set from hinumber to lonumber separeted folde by step, basefolder the directory on your local computer hinumber=28874 lonumber=24000 step=1000 basefolder='C:\\SQLSatruday\\presentations\\' # download routine for i in range(hinumber, lonumber,-1): print('i:',str(i)) if i % step ==0 or i==hinumber: print(i) subdir=str(i) downloadfolder=basefolder+subdir print('basefolder:',basefolder) print('subdir:',subdir) print('downloadfolder',downloadfolder) if not os.path.exists(downloadfolder): os.makedirs(downloadfolder) file_base_url='https://www.sqlsaturday.com/SessionDownload.aspx?suid=' file_url = file_base_url+ str(i) file_name = wget.download(file_url,out=downloadfolder) directory= os.path.dirname(file_name) origpath=os.path.realpath(file_name) filenev=os.path.basename(file_name) print(' origpath:',origpath) print(' Filenev:',filenev) strfilenev=str(filenev) if strfilenev=='SessionDownload.aspx' or strfilenev == 'SessionDownload (1).aspx' : print('\033[31m' + str(i) + '\033[0m' ) f= open( basefolder+"\\download_"+subdir+"_url_error.txt","a") f.write(file_url+'\n') f.close() ujfilenev=str(i)+'_'+str(filenev) ujutvonal=directory+'\\' +ujfilenev move(origpath,ujutvonal) print('new downloaded file:',ujutvonal) |
The scripts create a subfolder for every 1000 files, if it stops (I had problem with two special filename, you can rewrite the hinumber and lownumber and continue)
Be aware!
So the SQL Pass is a very large community. If you want to download around 3500 pdf , 4000 ppt and 8000 zip files with a lot of stuff, you need at least 50 GB disk space.
I am sure this big community will survive in a new form.
Enjoy the knowledge of SQL Server community!